Monitoring Kubernetes performance metrics
Last updated: March 10, 2020

As explained in Part 1 of this series, monitoring a Kubernetes environment requires a different approach than monitoring VM-based workloads or even unorchestrated containers. The good news is that Kubernetes is built around objects such as Deployments and DaemonSets, which provide long-lived abstractions on top of dynamic container workloads. So even though individual containers and pods may come and go, you can use these abstractions to aggregate your data and monitor the performance of your workloads.
Additionally, Kubernetes provides a wealth of APIs for automation and cluster management, including robust APIs for collecting performance data. In this part of the series, we’ll dig into the data you can collect from these APIs to monitor the Kubernetes platform itself. The metrics we’ll cover in this post fall into three broad categories:
- Cluster state metrics
- Resource metrics from Kubernetes nodes and pods
- Work metrics from the Kubernetes Control Plane
We’ll also touch on the value of collecting Kubernetes events. This article references metric categories and terminology from our Monitoring 101 series, which provides a framework for metric collection and alerting.
Key Kubernetes objects
A Kubernetes cluster is made up of two primary node types: worker nodes, which run your containerized workloads, and one or more Control Plane nodes. The Control Plane, which we’ll cover in more detail below, provides centralized APIs and internal services for cluster management. It also maintains a record of cluster state in an etcd key-value store. The data store instances may be co-located with the other Control Plane services on the dedicated Control Plane nodes or hosted externally on their own separate hosts.
Worker nodes are host VMs. Each one has a kubelet process that monitors the worker node and acts as the point of contact between that node and the Control Plane. The kubelet receives requests from the Control Plane and instructs the worker node’s runtime environment to create and manage pods to run the workloads.
Pods are self-contained, easily replicable objects comprising one or more containers that share storage and a network IP address. Each pod is often just a single container, but pods can also be used to bundle containers that must run together. For example, a pod might contain an instance of a custom microservice along with a “sidecar” container running Envoy to handle traffic to and from the service.
Where Kubernetes metrics come from
The Kubernetes ecosystem includes two complementary add-ons for aggregating and reporting valuable monitoring data from your cluster: Metrics Server and kube-state-metrics.
Metrics Server collects resource usage statistics from the kubelet on each node and provides aggregated metrics through the Metrics API. Metrics Server stores only near-real-time metrics in memory, so it is primarily valuable for spot checks of CPU or memory usage, or for periodic querying by a full-featured monitoring service that retains data over longer timespans.
kube-state-metrics is a service that makes cluster state information easily consumable. Whereas Metrics Server exposes metrics on resource usage by pods and nodes, kube-state-metrics listens to the Control Plane API server for data on the overall status of Kubernetes objects (nodes, pods, Deployments, etc.), as well as the resource limits and allocations for those objects. It then generates metrics from that data that are available through the Metrics API.
In Part 3 of this series, we’ll go into detail about how you can access metrics with Metrics Server and kube-state-metrics.
Key Kubernetes performance metrics to monitor
Cluster state metrics
The Kubernetes API server emits data about the count, health, and availability of various Kubernetes objects, such as pods. Internal Kubernetes processes and components use this information to track whether pods are being launched and maintained as expected and to properly schedule new pods. These cluster state metrics can also provide you with a high-level view of your cluster and its state. They can surface issues with nodes or pods, alerting you to the possibility that you need to investigate a bottleneck or scale out your cluster.
For Kubernetes objects that are deployed to your cluster, several similar but distinct metrics are available, depending on what type of controller manages those objects. Two important types of controllers are:
- Deployments, which create a specified number of pods (often combined with a Service that creates a persistent point of access to the pods in the Deployment)
- DaemonSets, which ensure that a particular pod is running on every node (or on a specified set of nodes)
You can learn about these and other types of controllers in the Kubernetes documentation.
Retrieving cluster state metrics
Some cluster state statistics are automatically available from your cluster and can be retrieved using the kubectl command line utility. For example, you can use kubectl to retrieve a list of Kubernetes Deployments and their current status:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 18sAs mentioned above, the kube-state-metrics add-on makes this data more accessible and consumable, especially for long-term monitoring, so in the table below we will provide the relevant metric names from kube-state-metrics where applicable.
| Metric | Name in kube-state-metrics | Description | Metric type |
|---|---|---|---|
| Node status | kube_node_status_condition | Current health status of the node. Returns a set of node conditions (listed below) and true, false, or unknown for each | Resource: Availability |
| Desired pods | kube_deployment_spec_replicas or kube_daemonset_status_desired_number_scheduled | Number of pods specified for a Deployment or DaemonSet | Other |
| Current pods | kube_deployment_status_replicas or kube_daemonset_status_current_number_scheduled | Number of pods currently running in a Deployment or DaemonSet | Other |
| Available pods | kube_deployment_status_replicas_available or kube_daemonset_status_number_available | Number of pods currently available for a Deployment or DaemonSet | Resource: Availability |
| Unavailable pods | kube_deployment_status_replicas_unavailable or kube_daemonset_status_number_unavailable | Number of pods currently not available for a Deployment or DaemonSet | Resource: Availability |
Metric to alert on: Node status
This cluster state metric provides a high-level overview of a node’s health and whether the scheduler can place pods on that node. It runs checks on the following node conditions:
OutOfDiskReady(node is ready to accept pods)MemoryPressure(node memory is too low)PIDPressure(too many running processes)DiskPressure(remaining disk capacity is too low)NetworkUnavailable
Each check returns true, false, or, if the worker node hasn’t communicated with the relevant Control Plane node for a grace period (which defaults to 40 seconds), unknown. In particular, the Ready and NetworkUnavailable checks can alert you to nodes that are unavailable or otherwise not usable so that you can troubleshoot further. If a node returns true for the MemoryPressure or DiskPressure check, the kubelet attempts to reclaim resources. This includes garbage collection and possibly deleting pods from the node.
Metrics to alert on: Desired vs. current pods
While you can manually launch individual pods for small-scale experiments, in production you will more likely use controllers to describe the desired state of your cluster and automate the creation of pods. For example, a Deployment manifest includes a statement of how many replicas of each pod should run. This ensures that the Control Plane will attempt to keep that many replicas running at all times, even if one or more nodes or pods crashes. Alternatively, a DaemonSet launches one pod on every node in your cluster (unless you specify a subset of nodes). This is often useful for installing a monitoring agent or other node-level utility across your cluster.
Kubernetes provides metrics that reflect the number of desired pods (e.g., kube_deployment_spec_replicas) and the number of currently running pods (e.g., kube_deployment_status_replicas). Typically, these numbers should match unless you are in the midst of a deployment or other transitional phase, so comparing these metrics can alert you to issues with your cluster. In particular, a large disparity between desired and running pods can point to bottlenecks, such as your nodes lacking the resource capacity to schedule new pods. It could also indicate a problem with your configuration that is causing pods to fail. In either case, inspecting pod logs can provide insight into the cause, as we’ll detail in Part 3 of this series.
Metrics to watch: Available and unavailable pods
A pod may be running but not available, meaning it is not ready and able to accept traffic. This is normal during certain circumstances, such as when a pod is newly launched or when a change is made and deployed to the specification of that pod. But if you see spikes in the number of unavailable pods, or pods that are consistently unavailable, it might indicate a problem with their configuration.

In particular, a large number of unavailable pods might point to poorly configured readiness probes. Developers can set readiness probes to give a pod time to perform initial startup tasks (such as loading large files) before accepting requests so that the application or service doesn’t experience problems. Checking a pod’s logs can provide clues as to why it is stuck in a state of unavailability.
How Kubernetes manages resource usage
Monitoring memory, CPU, and disk usage within nodes and pods can help you detect and troubleshoot application-level problems. But monitoring the resource usage of Kubernetes objects is not as straightforward as monitoring a traditional application. In Kubernetes, you still need to track the actual resource usage of your workloads, but those statistics become more actionable when you monitor them in the context of resource requests and limits, which govern how Kubernetes manages finite resources and schedules workloads across the cluster. In the metric table below, we’ll provide details on how you can monitor actual utilization alongside the requests and limits for a particular resource.
Requests and limits
In a manifest, you can declare a request and a limit for CPU (measured in cores) and memory (measured in bytes) for each container running on a pod. A request is the minimum amount of CPU or memory that a node will allocate to the container; a limit is the maximum amount that the container will be allowed to use. The requests and limits for an entire pod are calculated from the sum of the requests and limits of its constituent containers.
Requests and limits do not define a pod’s actual resource utilization, but they significantly affect how Kubernetes schedules pods on nodes. Specifically, new pods will only be placed on a node that can meet their requests. Requests and limits are also integral to how a kubelet manages available resources by terminating pods (stopping the processes running on its containers) or evicting pods (deleting them from a node), which we’ll cover in more detail below.
You can read more in the Kubernetes documentation about configuring requests and limits and how Kubernetes responds when resources run low.
Resource metrics
Comparing resource utilization with resource requests and limits will provide a more complete picture of whether your cluster has the capacity to run its workloads and accommodate new ones. It’s important to keep track of resource usage at different layers of your cluster, particularly for your nodes and for the pods running on them.
We will discuss methods for collecting resource metrics from your nodes, pods, and containers in Part 3 of this series.
| Metric | Name in kube-state-metrics | Description | Metric type |
|---|---|---|---|
| Memory requests | kube_pod_container_resource_requests_memory_bytes | Total memory requests (bytes) of a pod | Resource: Utilization |
| Memory limits | kube_pod_container_resource_limits_memory_bytes | Total memory limits (bytes) of a pod | Resource: Utilization |
| Allocatable memory | kube_node_status_allocatable_memory_bytes | Total allocatable memory (bytes) of the node | Resource: Utilization |
| Memory utilization | N/A | Total memory in use on a node or pod | Resource: Utilization |
| CPU requests | kube_pod_container_resource_requests_cpu_cores | Total CPU requests (cores) of a pod | Resource: Utilization |
| CPU limits | kube_pod_container_resource_limits_cpu_cores | Total CPU limits (cores) of a pod | Resource: Utilization |
| Allocatable CPU | kube_node_status_allocatable_cpu_cores | Total allocatable CPU (cores) of the node | Resource: Utilization |
| CPU utilization | N/A | Total CPU in use on a node or pod | Resource: Utilization |
| Disk utilization | N/A | Total disk space used on a node | Resource: Utilization |
Metrics to alert on: Memory limits per pod vs. memory utilization per pod
When specified, a memory limit represents the maximum amount of memory a node will allocate to a container. If a limit is not provided in the manifest and there is not an overall configured default, a pod could use the entirety of a node’s available memory. Note that a node can be oversubscribed, meaning that the sum of the limits for all pods running on a node might be greater than that node’s total allocatable memory. This requires that the pods’ defined requests are below the limit. The node’s kubelet will reduce resource allocation to individual pods if they use more than they request so long as that allocation at least meets their requests.
Tracking pods’ actual memory usage in relation to their specified limits is particularly important because memory is a non-compressible resource. In other words, if a pod uses more memory than its defined limit, the kubelet can’t throttle its memory allocation, so it terminates the processes running on that pod instead. If this happens, the pod will show a status of OOMKilled.
Comparing your pods’ memory usage to their configured limits will alert you to whether they are at risk of being OOM killed, as well as whether their limits make sense. If a pod’s limit is too close to its standard memory usage, the pod may get terminated due to an unexpected spike. On the other hand, you may not want to set a pod’s limit significantly higher than its typical usage because that can lead to poor scheduling decisions. For example, a pod with a memory request of 1GiB and a limit of 4GiB can be scheduled on a node with 2GiB of allocatable memory (more than sufficient to meet its request). But if the pod suddenly needs 3GiB of memory, it will be killed even though it’s well below its memory limit.
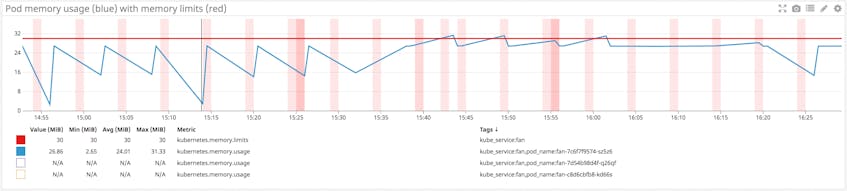
Metric to alert on: Memory utilization
Keeping an eye on memory usage at the pod and node level can provide important insight into your cluster’s performance and ability to successfully run workloads. As we’ve seen, pods whose actual memory usage exceeds their limits will be terminated. Additionally, if a node runs low on available memory, the kubelet flags it as under memory pressure and begins to reclaim resources.
In order to reclaim memory, the kubelet can evict pods, meaning it will delete these pods from the node. The Control Plane will attempt to reschedule evicted pods on another node with sufficient resources. If your pods’ memory usage significantly exceeds their defined requests, it can cause the kubelet to prioritize those pods for eviction, so comparing requests with actual usage can help surface which pods might be vulnerable to eviction.
Habitually exceeding requests could also indicate that your pods are not configured appropriately. As mentioned above, scheduling is largely based on a pod’s request, so a pod with a bare-minimum memory request could be placed on a node without enough resources to withstand any spikes or increases in memory needs. Correlating and comparing each pod’s actual utilization against its requests can give insight into whether the requests and limits specified in your manifests make sense, or if there might be some issue that is causing your pods to use more resources than expected.
Monitoring overall memory utilization on your nodes can also help you determine when you need to scale your cluster. If node-level usage is high, you may need to add nodes to the cluster to share the workload.
Metrics to watch: Memory requests per node vs. allocatable memory per node
Memory requests, as discussed above, are the minimum amounts of memory a node’s kubelet will assign to a container. If a request is not provided, it will default to whatever the value is for the container’s limit (which, if also not set, could be all memory on the node). Allocatable memory reflects the amount of memory on a node that is available for pods. Specifically, it takes the overall capacity and subtracts memory requirements for OS and Kubernetes system processes to ensure they will not fight user pods for resources.
Although memory capacity is a static value, maintaining an awareness of the sum of pod memory requests on each node, versus each node’s allocatable memory, is important for capacity planning. These metrics will inform you if your nodes have enough capacity to meet the memory requirements of all current pods and whether the Control Plane is able to schedule new ones. Kubernetes’s scheduling process uses several levels of criteria to determine if it can place a pod on a specific node. One of the initial tests is whether a node has enough allocatable memory to satisfy the sum of the requests of all the pods running on that node, plus the new pod.
Comparing memory requests to capacity metrics can also help you troubleshoot problems with launching and running the desired number of pods across your cluster. If you notice that your cluster’s count of current pods is significantly less than the number of desired pods, these metrics might show you that your nodes don’t have the resource capacity to host new pods, so the Control Plane is failing to find a node to assign desired pods to. One straightforward remedy for this issue is to provision more nodes for your cluster.
Metric to alert on: Disk utilization
Like memory, disk space is a non-compressible resource, so if a kubelet detects low disk space on its root volume, it can cause problems with scheduling pods. If a node’s remaining disk capacity crosses a certain resource threshold, it will get flagged as under disk pressure. The following are the default resource thresholds for a node to come under disk pressure:
| Disk pressure signal | Threshold | Description |
|---|---|---|
| imagefs.available | 15% | Available disk space for the imagefs filesystem, used for images and container-writable layers |
| imagefs.inodesFree | 5% | Available index nodes for the imagefs filesystem |
| nodefs.available | 10% | Available disk space for the root filesystem |
| nodefs.inodesFree | 5% | Available index nodes for the root filesystem |
Crossing one of these thresholds leads the kubelet to initiate garbage collection to reclaim disk space by deleting unused images or dead containers. As a next step, if it still needs to reclaim resources, it will start evicting pods.
In addition to node-level disk utilization, you should also track the usage levels of the volumes used by your pods. This helps you stay ahead of problems at the application or service level. Once these volumes have been provisioned and attached to a node, the node’s kubelet exposes several volume-level disk utilization metrics, such as the volume’s capacity, utilization, and available space. These volume metrics are available from Kubernetes’s Metrics API, which we’ll cover in more detail in Part 3 of this series.
If a volume runs out of remaining space, any applications that depend on that volume will likely experience errors as they try to write new data to the volume. Setting an alert to trigger when a volume reaches 80 percent usage can give you time to create new volumes or scale up the storage request to avoid problems.
Metrics to watch: CPU requests per node vs. allocatable CPU per node
As with memory, allocatable CPU reflects the CPU resources on the node that are available for pod scheduling, while requests are the minimum amount of CPU a node will attempt to allocate to a pod.
As mentioned above, Kubernetes measures CPU in cores. Tracking overall CPU requests per node and comparing them to each node’s allocatable CPU capacity is valuable for capacity planning of a cluster and will provide insight into whether your cluster can support more pods.
Metrics to watch: CPU limits per pod vs. CPU utilization per pod
These metrics let you track the maximum amount of CPU a node will allocate to a pod compared to how much CPU it’s actually using. Unlike memory, CPU is a compressible resource. This means that if a pod’s CPU usage exceeds its defined limit, the node will throttle the amount of CPU available to that pod but allow it to continue running. This throttling can lead to performance issues, so even if your pods won’t be terminated, keeping an eye on these metrics will help you determine if your limits are configured properly based on the pods’ actual CPU needs.
Metric to watch: CPU utilization
Tracking the amount of CPU your pods are using compared to their configured requests and limits, as well as CPU utilization at the node level, will give you important insight into cluster performance. Much like a pod exceeding its CPU limits, a lack of available CPU at the node level can lead to the node throttling the amount of CPU allocated to each pod.
Measuring actual utilization compared to requests and limits per pod can help determine if these are configured appropriately and your pods are requesting enough CPU to run properly. Alternatively, consistently higher than expected CPU usage might point to problems with the pod that need to be identified and addressed.
Control Plane metrics
As mentioned briefly above, the Kubernetes Control Plane provides several core services and resources for cluster management:
- the API server is the gateway through which developers and administrators query and interact with the cluster
- controller managers implement and track the lifecycle of the different controllers that are deployed to the cluster (e.g., to regulate the replication of workloads)
- schedulers query the state of the cluster and schedule and assign workloads to worker nodes
- etcd data stores maintain a record of the state of the cluster in a distributed key-value store so that other components can ensure that all worker nodes are healthy and running the desired workloads
Kubernetes exposes metrics for each of these components, which you can collect and track to ensure that your cluster’s central nervous system is healthy. Note that in managed Kubernetes environments (such as Google Kubernetes Engine or Amazon Elastic Kubernetes Service clusters), the Control Plane is managed by the cloud provider, and you may not have access to all the components and metrics listed below. Also, the availability or names of certain metrics may be different depending on which version of Kubernetes you are using.
| Metric | Description | Metric type |
|---|---|---|
etcd_server_has_leader | Indicates whether the member of the cluster has a leader (1 if a leader exists, 0 if not) | Resource: Availability |
etcd_server_leader_changes_seen_total | Counter of leader changes seen by the cluster member | Other |
apiserver_request_latencies_count | Count of requests to the API server for a specific resource and verb | Work: Throughput |
apiserver_request_latencies_sum | Sum of request duration to the API server for a specific resource and verb, in microseconds | Work: Performance |
workqueue_queue_duration_seconds (v1.14+) | Total number of seconds that items spent waiting in a specific work queue | Work: Performance |
workqueue_work_duration_seconds (v 1.14+) | Total number of seconds spent processing items in a specific work queue | Work: Performance |
scheduler_schedule_attempts_total | Count of attempts to schedule a pod, broken out by result | Work: Throughput |
scheduler_e2e_scheduling_latency_microseconds (pre-v1.14) or scheduler_e2e_scheduling_duration_seconds (v1.14+) | Total elapsed latency in scheduling workload pods on worker nodes | Work: Performance |
Metric to alert on: etcd_server_has_leader
Except during leader election events, the etcd cluster should always have a leader, which is necessary for the operation of the key-value store. If a particular member of an etcd cluster reports a value of 0 for etcd_server_has_leader (perhaps due to network issues), that member of the cluster does not recognize a leader and is unable to serve queries. Therefore, if every cluster member reports a value of 0, the entire etcd cluster is down. A failed etcd key-value store deprives Kubernetes of necessary information about the state of cluster objects, and prevents Kubernetes from making any changes to cluster state. Because of its critical role in cluster operations, etcd provides snapshot and recovery operations to mitigate the impact of failure scenarios.
Metric to watch: etcd_server_leader_changes_seen_total
The metric etcd_server_leader_changes_seen_total tracks the number of leader transitions within the cluster. Frequent leader changes, though not necessarily damaging on their own, can alert you to issues with connectivity or resource limitations in the etcd cluster.
To learn more about how etcd works and key metrics you should monitor, see this blog post.
Metrics to watch: apiserver_request_latencies_count and apiserver_request_latencies_sum
Kubernetes provides metrics on the number and duration of requests to the API server for each combination of resource (e.g., pods, Deployments) and verb (e.g., GET, LIST, POST, DELETE). By dividing the summed latency for a specific type of request by the number of requests of that type, you can compute a per-request average latency. You can also track these metrics over time and divide their deltas to compute a real-time average. By tracking the number and latency of specific kinds of requests, you can see if the cluster is falling behind in executing any user-initiated commands to create, delete, or query resources, likely due to the API server being overwhelmed with requests.
Metrics to watch: workqueue_queue_duration_seconds and workqueue_work_duration_seconds
These latency metrics provide insight into the performance of the controller manager, which queues up each actionable item (such as the replication of a pod) before it’s carried out. Each metric is tagged with the name of the relevant queue, such as queue:daemonset or queue:node_lifecycle_controller. The metric workqueue_queue_duration_seconds tracks how much time, in aggregate, items in a specific queue have spent awaiting processing, whereas workqueue_work_duration_seconds reports how much time it took to actually process those items. If you see a latency increase in the automated actions of your controllers, you can look at the logs for the controller manager to gather more details about the cause.
Metrics to watch: scheduler_schedule_attempts_total and end-to-end scheduling latency
You can track the work of the Kubernetes scheduler by monitoring its overall number of attempts to schedule pods on nodes, as well as the end-to-end latency of carrying out those attempts. The metric scheduler_schedule_attempts_total breaks out the scheduler’s attempts by result (error, schedulable, or unschedulable), so you can identify problems with matching pods to worker nodes. An increase in unschedulable pods indicates that your cluster may lack the resources needed to launch new pods, whereas an attempt that results in an error status reflects an internal issue with the scheduler itself.
The end-to-end latency metrics report both how long it takes to select a node for a particular pod, as well as how long it takes to notify the API server of the scheduling decision so it can be applied to the cluster. If you notice a discrepancy between the number of desired and current pods, you can dig into these latency metrics to see if a scheduling issue is behind the lag. Note that the end-to-end latency is reported differently depending on the version of Kubernetes you are running (pre-v1.14 or 1.14+), with different time units as well.
Kubernetes events
Collecting events from Kubernetes and from the container engine (such as Docker) allows you to see how pod creation, destruction, starting, or stopping affects the performance of your infrastructure—and vice versa.
While Docker events trace container lifecycles, Kubernetes events report on pod lifecycles and deployments. Tracking Kubernetes Pending pods and pod failures, for example, can point you to misconfigured launch manifests or issues of resource saturation on your nodes. That’s why you should correlate events with Kubernetes metrics for easier investigation.
Watching the conductor and the orchestra
In this post, we’ve highlighted a number of core Kubernetes components, as well as the metrics and events that can help you track their health and performance over time. Part 3 of this series will show you how you can use built-in Kubernetes APIs and utilities to collect all the metrics highlighted here, so that you can get deep visibility into your container infrastructure and workloads. Read on . . .
Source Markdown for this post is available on GitHub. Questions, corrections, additions, etc.? Please let us know.
